| Дальше
|
Назад |
Начало |
Конец |
Список
|
2.7. Оценка качества водных экосистем по многомерным эмпирическим данным
Мем № 18: “Каковыми бы сложными не были состав элементов, структура взаимосвязей или материально-энергетические процессы в реальной экосистеме, все они, в конечном итоге, сводятся для наблюдателя всего к двум показателям: численности и биомассе особей отдельных видов, измеренных в пространственно-временном аспекте. Роль гидробиолога состоит в том, чтобы по этим двум показателям восстановить всю сложность реального мира, используя свой опыт и "арсенал" математических формул”
[Авторы настоящей книги; предлагается впервые].
Общая постановка задачи
Несмотря на то, что в нашей стране нет общепринятой системы оценки качества вод по гидробиологическим показателям [Винберг, 1979а], основной задачей классической гидробиологии остается таксация водоемов по степени загрязнения. Основные принципы такой оценки в конечном итоге сводятся к следующим формальным аксиоматическим предпосылкам, без выполнения которых эта задача не имеет смысла.
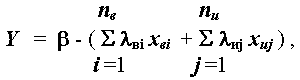 .
. (2.5)
(2.5)
где: l вi и l иj – найденные коэффициенты статистической модели, b – свободный член.
Величины l вi при неизвестных Xвi в уравнении (2.5) играют роль "индикаторных валентностей": большие положительные значения связаны с чувствительными видами-индикаторами воды высокого качества, отрицательные значения (< 0) – с видами, характерными для загрязненных водоемов, а коэффициенты, близкие к нулю – с эврибионтными видами, не являющимися индикаторами.
Подмножество обобщенных индексов Xиj может включать любые, в том числе, такие общепризнанные показатели как информационный индекс Шеннона, биотический индекс Вудивисса, составляющие функционально-энергетического баланса, сапробиологические показатели, коэффициенты, основанные на учете индикаторных групп гидробионтов (олигохет, хирономид и др.). Единственным критерием для включения индекса в модель является его предполагаемая информативность, т.е. возможность учесть при анализе данных новые информационные аспекты, не содержащиеся в явном виде в исходном пространстве видов, а также использовать в конкретных случаях анализа весь ретроспективный опыт и закономерности, выявленные исследователями на водоемах других регионов. В частности, в подмножество обобщенных индексов могут входить абсолютные или относительные показатели обилия отдельных трофико-таксономических групп (см. главу 4).
Статистическое моделирование, всегда основанное на апостериорной информации, предполагает наличие обучающей выборки: таблицы с эмпирическими данными, где каждой k-й строке {x1, …, xi, …, xn} поставлено в соответствие строго определенное значение показателя качества yk . Если этот показатель измерен в непрерывных шкалах, то решается задача множественной регрессии. Если yk имеет смысл класса качества и представлен шкалой наименований или порядковой шкалой, то решается задача распознавания образов. В этом случае обучающая последовательность представляет собой таблицу, разбитую на L непересекающихся подмножеств строк, причем любому из L классов принадлежит не менее одного объекта. Содержательный смысл задаваемой системы классификации {у1, у2, …, yL} не имеет никакого значения для последующего изложения и может быть вполне произвольным (например: любые градации сапробности, токсобности, классов качества вод, типов водоемов, природно-климатических зон и т.д.) Можно упомянуть особый случай представления класса качества yk в бинарной (альтернативной) шкале измерения, когда используются лишь две градации, например, "плохое качество / хорошее качество".
С точки зрения общих концепций классификации и прогнозирования, каких-либо четких отличий между регрессионным анализом и распознаванием образов нет. Приведем, в частности, обобщенную формулировку задач статистики для таблицы наблюдений Х, с предельной ясностью сделанную Г.С. Лбовым [1981], который выделил четыре классические постановки:
Каждая из перечисленных постановок сводится, в сущности, к единой задаче заполнения пропусков в таблице данных. При автоматической группировке объектов в таблицу добавляется новый столбец, содержащий информацию о разбиении всего множества объектов на группы схожих. Для иных постановок прогнозируются неизвестные значения признаков у тех объектов, где имеется пропущенная информация (т.е. смысл задачи заполнения пропусков является эквивалентной классическому восстановлению неизвестных функциональных зависимостей по априори неполной таблице экспериментальных данных).
Процедуры многомерного статистического анализа сводятся к идентификации математических моделей, отражающих состояние объекта. Идентификация – это:
Задача идентификации уравнений регрессии в прикладном смысле сводится к расчету и последующему анализу модели (2.5), т.е. выбору комплекса информативных переменных, наилучшим образом объясняющим существующие закономерности (структурная идентификация), подбору оптимальных коэффициентов уравнения или частных выражений для составляющих компонент (численная и функциональная идентификация).
Любая гидробиологическая среда представляет собой большой, сложный, слабо детерминированный и эволюционирующий объект исследования. Поэтому, как показывает практика, предположения о линейности аппроксимирующей функции (2.5), как правило, лишены оснований. Теория самоорганизации моделей показывает, что огромное большинство процессов в природе может быть описано, например, в виде полиномов высокой степени, являющихся частным случаем обобщенного полинома Колмогорова–Габора [Габор, 1972; Ивахненко с соавт., 1976]:
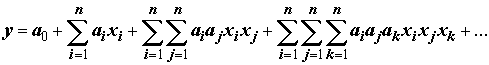 .(2.6)
.(2.6)
Число членов полного полинома равно 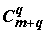 , где m – число переменных, q – степень полинома, и уже при n=q=7 достигает 3600. Поэтому основная задача моделирования сложных систем с использованием регрессионных уравнений заключается в том, чтобы исключить в полиноме (2.6) подмножество "лишних" неинформативных коэффициентов и сохранить необходимое и достаточное сочетание "объясняющих членов". Сложность синтезированной модели будет оптимальной, если необходимая адекватность обеспечивается при минимальном количестве составляющих ее элементов [Эшби, 1959].
, где m – число переменных, q – степень полинома, и уже при n=q=7 достигает 3600. Поэтому основная задача моделирования сложных систем с использованием регрессионных уравнений заключается в том, чтобы исключить в полиноме (2.6) подмножество "лишних" неинформативных коэффициентов и сохранить необходимое и достаточное сочетание "объясняющих членов". Сложность синтезированной модели будет оптимальной, если необходимая адекватность обеспечивается при минимальном количестве составляющих ее элементов [Эшби, 1959].
Для реализации этих условий необходим набор алгоритмов и методов построения различных эмпирических моделей прогнозирования (2.5), который бы удовлетворял следующим условиям:
В этих условиях методы традиционной параметрической статистики не всегда могут быть работоспособны, поскольку требуют либо ощутимого объема исходных данных, либо некоторых предположений о виде функций распределения. Определенную альтернативу им составляют алгоритмы распознавания образов.
Методы распознавания образов
Как отмечалось выше, реальные гидробиологические объекты отличаются друг от друга какими-либо свойствами, но в то же время, многие из них обладают и некоторой общностью, что позволяет объединять объекты в классы. В математической литературе часто используется тождественное “классу” понятие “образа” и многие задачи классификации объединены под названием "проблемы распознавания образов". Наиболее удачно смысл этого термина сформулирован Н.Г. Загоруйко [1972]: “Под образом будем понимать наименование области в пространстве признаков, в которой отображается множество объектов или явлений реального мира”.
Понятие “образа” может быть в разной степени абстрактным по отношению к изучаемым предметам и явлениям. Например, в объективной реальности не существует "экосистемы вообще", а существуют только отдельные измерения, наделенные некоторыми общими свойствами и объединенные исследователем в некоторый образ "экосистема". В нашем случае "экосистемой" можно назвать и некоторую небольшую географическую общность точек наблюдения (створ, станция), и произвольный участок реки, и отдельную реку или некоторую их совокупность, и весь Волжский бассейн в целом. В рамках тех формально-логических определений "экосистемы", которые существуют в настоящее время, корректность перечисленных утверждений нельзя ни доказать, ни опровергнуть (что вытекает из теоремы о "неполноте" К. Гёделя).
В рассматриваемом случае классы эквивалентности с той или иной степенью обоснованности задаются самим исследователем, т.е. рассматривается задача "распознавания с учителем", что отличает ее от описанного выше кластерного анализа. При этом выделяемые самостоятельные единицы ("экземпляры") образов группируются на основе некоторых содержательных представлений или используется внешняя дополнительная информация о сходстве и различии объектов в контексте решаемой задачи (например, постулируются образ буквы “А”, границы реки Сок или в отдельный "грязный" класс выделяются измерения с БПК5 > 3).
Предтечей математических методов распознавания образов явился дискриминантный анализ, предложенный в 1936 г. Р. Фишером (R. Fisher), – классическая ветвь биометрии, которая уже более 60 лет находит применение в самых разных областях биологической систематики и медицинской диагностики [Урбах, 1964; Дуда, Харт, 1978; Кравцов, Милютин, 1981; Айвазян с соавт., 1989; Ким с соавт., 1989]. Этот вид анализа обобщает несколько тесно связанных статистических процедур, относящихся к подмножеству линейных методов, поскольку модель классификации линейна относительно дискриминантных функций и напоминает множественную линейную регрессию. С другой стороны, основная идея дискриминантного анализа заключается в том, чтобы определить, отличаются ли совокупности по среднему значению линейной комбинации исходных переменных, и затем использовать эту комбинацию, чтобы предсказать для новых членов их принадлежность к той или иной группе. Поставленная таким образом задача о дискриминантной функции может быть сформулирована как задача многомерного дисперсионного анализа (МANOVA).
Множество алгоритмов распознавания образов, при всей их несхожести, методически основаны на одной предпосылке – гипотезе компактности [Айвазян с соавт., 1989; Кольцов, 1989], т.е. “в используемом пространстве признаков измерения, принадлежащие одному и тому же классу, близки между собой, а измерения, принадлежащие разным классам хорошо разделимы друг от друга”. Существуют разные версии классификации алгоритмов распознавания, предлагаемые Ю.Л. Барабашем с соавторами [1967], Л.Т. Кузиным [1979], П. Уинстоном [1980], В.И. Васильевым [1983], А.Л.Гореликом и В.А. Скрипкиным [1984], Я.З. Цыпкиным [1984] и др. Например, в работах Е.В. Луценко [1996, 2002] используется типология методов распознавания образов на основе двух основных способов представления знаний:
Обобщенные выводы из этого детального обзора методов распознавания мы представили в табл. 2.3, хотя не во всем согласны с излишне категоричными мнениями автора о недостатках анализируемых алгоритмов.
Обзор методов автоматической классификации применительно к проблемам геоботаники был выполнен также одним из соавторов книги [Розенберг, 1977].
Таблица 2.3
Классификация методов распознавания образов; области их применения, наличие ограничений и недостатков [Луценко, 1996]
|
Классификация |
Область |
Ограничения |
|
|
Методы, основанные на операциях с признаками (интенсиональные методы) |
Методы, основанные на оценках плотностей распределения значений признаков |
Задачи с известным распределением (как правило, нормальным), необходимость набора большой статистики. |
Необходимость перебора всей обучающей выборки при распознавании, высокая чувствительность к репрезентативности обучающей выборки и артефактам. |
|
Методы, основанные на предположениях о классе решающих функций |
Классы должны быть хорошо разделяемыми, система признаков - ортонормированной |
Должен быть заранее известен вид решающей функции. Невозможность учета новых знаний о корреляциях между признаками. |
|
|
Логические методы |
Задачи небольшой размерности пространства признаков. |
При отборе логических решающих правил (конъюнкций) необходим полный перебор. Высокая вычислительная трудоемкость. |
|
|
Лингвистические (структурные) методы |
Задачи небольшой размерности пространства признаков. |
Задача восстановления (определения) грамматики по некоторому множеству высказываний (описаний объектов), является трудно формализуемой. |
|
|
Методы, основанные на операциях с объектами (экстенсиональные методы) |
Метод сравнения с прототипом |
Задачи небольшой размерности пространства признаков. |
Высокая зависимость результатов классификации от меры расстояния (метрики). |
|
Метод k-ближайших соседей |
Задачи небольшой размерности по количеству классов и признаков. |
Высокая зависимость результатов классификации от меры расстояния (метрики). Необходимость полного перебора обучающей выборки при распознавании. Вычислительная трудоемкость. |
|
|
Алгоритмы вычисления оценок |
Задачи небольшой размерности по количеству классов и признаков. |
Зависимость результатов классификации от меры расстояния (метрики). Необходимость полного перебора обучающей выборки при распознавании. Высокая техническая сложность метода. |
|
|
Коллективы решающих правил |
Задачи небольшой размерности по количеству классов и признаков. |
Очень высокая техническая сложность метода, теоретические проблемы, как при определении областей компетенции частных методов, так и в самих частных методах. |
|
Методы, основанные на оценках плотностей распределения значений признаков, заимствованы из классической теории статистических решений [Кендалл, Сьюарт, 1973], в которой объекты исследования рассматриваются как реализации многомерной случайной величины, распределенной в пространстве признаков по какому-либо закону [Афифи, Эйзен, 1982; Горелик, Скрипкин, 1984]. Эта группа методов использует ту или иную интерпретацию формулы условных вероятностей Т. Байеса (Т. Bayes) и имеет прямое отношение к методам дискриминантного анализа.
В группе методов, основанных на предположениях о классе решающих функций, считается известным общий вид уравнения разделяющей поверхности и задан функционал качества разбиения [Аркадьев, Браверман, 1971; Дуда, Харт,1978; Кольцов, 1989]. Самыми распространенными являются представления решающих функций в виде линейных и обобщенных нелинейных полиномов, что позволяет говорить об аналогии этих методов с частными реализациями регрессионного анализа. Функционал качества решающего правила обычно связывают с ошибкой классификации. Наиболее эффективными методами этой группы являются алгоритм построения оптимальной разделяющей гиперплоскости – "обобщенного портрета" [Вапник, Червоненкис, 1974] и разделение классов потенциальными функциями [Айзерман с соавт., 1970; Ту, Гонсалес, 1978].
Логические методы распознавания образов базируются на аппарате булевой алгебры логики и позволяют оперировать информацией, заключенной не только в отдельных признаках, но и в сочетаниях значений признаков [Горелик с соавт., 1985]. В главе 8 будут представлены результаты использования наиболее распространенного алгоритма этой группы –
"Кора" [Бонгард, 1967; Вайнцвайг, 1973], формирующего систему логических решающих правил в виде конъюнкций элементарных событий.Лингвистические методы распознавания образов основаны на использовании специальных грамматик (т.е. правил построения объектов из
"атомарных" элементов), порождающих языки, с помощью которых может описываться совокупность свойств распознаваемых объектов [Фу, 1977; Борисов с соавт., 1982; Горелик с соавт., 1985]. Синтаксические анализаторы, которые представляют полное описание объекта в виде дерева грамматического разбора, устанавливают его синтаксическую правильность, а именно, может ли фиксированная грамматика, описывающая некоторый класс, породить имеющееся описание объекта. В противном случае, объект либо отклоняется, либо подвергается анализу с помощью других грамматик, описывающих другие классы объектов.В экстенсиональных методах, в отличие от интенсионального направления, каждому изучаемому объекту в большей или меньшей мере придается самостоятельное диагностическое значение. Объекты в указанной группе методов играют роль диагностических прецедентов, при этом роль каждого из них может меняться в самых широких пределах: от главной до весьма косвенного участия в процессе классификации. По своей сути экстенсиональные методы рассматривают измерения как целостные феномены, каждый из которых индивидуален и имеет особенную диагностическую ценность, что определяет высокую эффективность этих методов для "чистого" прогноза. Однако задача восстановления закономерностей поведения объектов и интерпретации связей между варьируемыми переменными (т.е. функция объяснения) является для них трудно формализуемой.
Основными операциями в распознавании образов с помощью методов второй группы являются операции определения сходства и различия объектов. Дальнейшее разделение экстенсиональных методов на подклассы основано на различии в количестве диагностических прецедентов, которые используются для процесса решения: от одного в каждом распознаваемом классе (метод сравнения с прототипом) до полного объема выборки (алгоритмы АВО Ю.И. Журавлева [1978, Журавлев, Никифоров, 1971]). В частности, при классификации неизвестного объекта по методу k-ближайших соседей [Гренандер, 1979, 1981, 1983] находится заданное число (k) геометрически ближайших к нему в пространстве признаков других объектов с уже известной принадлежностью к распознаваемым классам. Дальнейшее решение принимается, например, с помощью простого подсчета голосов.
Так как различные алгоритмы распознавания проявляют себя по-разному на одной и той же выборке объектов, то закономерно встает вопрос о синтетическом решающем правиле, адаптивно использующем сильные стороны этих алгоритмов [Растригин, Эренштейн, 1981; Брусиловский, Розенберг, 1983; Брусиловский, 1987; Розенберг с соавт., 1994]. В коллективах решающих правил применяется двухуровневая схема распознавания. На первом уровне работают частные алгоритмы распознавания, результаты которых объединяются на втором уровне в блоке синтеза. Наиболее распространенные способы такого объединения основаны на выделении "областей компетентности", для которых доказана успешность работы какого-либо частного алгоритма распознавания.
Наряду с формальными методами распознавания образов полное и адекватное развитие в различных областях получили различные эвристические алгоритмы классификации и прогнозирования. Этот подход основывается на трудно формализуемых знаниях и интуиции исследователя, который сам определяет, какую информацию и каким образом нужно использовать для достижения требуемого эффекта распознавания. Примерами таких "авторских" методов являются процедура автоматической классификации геоботанических описаний [Розенберг, 1984] и алгоритм расчета индикаторных валентностей, представленный в главе 8.
Выбор методов многомерного анализа и особенности их реализации
Не только отклик Y модели (2.5), но и варьируемые переменные
Xвi, Xиj могут быть измерены в различных шкалах: количественной, порядковой или бинарной (альтернативной). В зависимости от размерности признакового пространства и шкал представления данных, могут быть использованы различные математические методы обработки многомерных наблюдений, каждый из которых имеет свою область и особенности применения. В рамках настоящей монографии мы были не в состоянии детально описать и выполнить расчеты для всех многочисленных алгоритмов параметрической статистики и распознавания образов, поэтому в главе 8 ограничились некоторым "джентльменским" набором, руководствуясь при отборе соображениями популярности, доступности и личными симпатиями. Область применения каждого из использованных методов для различных шкал переменных представлена в табл. 2.4.Таблица 2.4
Условия применения некоторых математических методов обработки многомерных наблюдений
|
Наименование метода или алгоритма |
Шкала измерения отклика Y |
Использование обобщенных индексов |
Шкала измерения обилия видов |
||||
|
Количес- |
Поряд- |
Альтер- |
Количес- |
Поряд- |
Альтер- |
||
|
1. Множественный регрессионный анализ |
Å |
nи > 0 |
|||||
|
2. Логистическая регрессия и упорядоченный пробит-анализ |
Å |
Å |
nи > 0 |
||||
|
3. Линейный дискриминантный анализ |
Å |
Å |
nи > 0 |
||||
|
4. Алгоритм вычисления индикаторных валентностей |
Å |
Å |
nи = 0 |
Å |
Å |
Å |
|
|
5. Построение разделяющей гиперплоскости (метод обобщенного портрета) |
Å |
nи = 0 |
Å |
Å |
|||
|
6. Алгоритмы алгебры логики (метод “Кора”) |
Å |
nи = 0 |
Å |
||||
При использовании параметрических методов статистики, представленных в табл. 2.4 пунктами 1-3, надежность получаемых результатов может в значительной мере зависеть от характера распределения исходных переменных. При анализе моделей часто используются такие предположения, как равенство дисперсионных матриц, равенство условных вероятностей событий в пределах класса и априорных вероятностей наблюдения классов, равенство функций потерь и т.д. Размерность признакового пространства практически не должна превышать 250-300, иначе могут возникнуть трудности вычислительного характера при матричных преобразованиях.
Как убедительно свидетельствует работа В.Н. Максимова с соавт. [1999], применение методов математической статистики, основанных на стандартном анализе дисперсий и ковариаций, оказывается малоэффективным для оценки причинно-следственных связей в пространстве гидробиологических переменных, которые представляют собой сильно разреженные матрицы большой размерности, заполненные в основном нулями. Поскольку основная часть таксономических групп зообентоса встречается всего в нескольких пробах из ста, нельзя говорить о сколько-нибудь приблизительной нормальности распределения обилия видов: признаковое пространство очень обширно, плохо обусловлено и скорее дискретно, чем непрерывно.
В связи с этим, применение классических параметрических методов 1-3 для обработки таблиц наблюдений в пространстве видов оказалось невозможным и, в качестве переменных моделей, использовались обобщенные индексы или показатели обилия таксонов, объединяющих группы видов. При использовании эвристических и непараметрических методов моделирования 4-6, которые не предъявляют жестких требований к таким свойствам исходных выборок, как нормальность распределения переменных, однородность дисперсий и т.п., имеется возможность детализации признакового пространства до уровня показателей обилия отдельных видов.
| Дальше
|
Назад |
Начало |
Конец |
Список
|