ЧАСТЬ 3. СТАТИСТИЧЕСКИЙ АНАЛИЗ В ГИДРОЭКОЛОГИИ:
ЗАДАЧИ И РЕШЕНИЯ
Мем № 27
: “Как ни странно, но задачи фитоиндикации, вероятностные по своей природе, до сих пор решаются в основном без использования каких-либо статистических методов” В.И. Василевич [1969].
Эта часть книги посвящена описанию конкретных методов математической статистики, распознавания образов и алгоритмов искусственного интеллекта применительно к анализу результатов гидроэкологического мониторинга.
Деление излагаемого материала на главы выполнено не вполне традиционным образом: не по "генетическому" сродству отдельных методов, а в соответствии с общностью постановок конкретных задач гидроэкологии и схемы последующей обработки данных:
- Глава 5 объединяет различные параметрические и непараметрические методы анализа, когда исследователь располагает одним или двумя вариационными рядами измерений, представленными в количественной шкале;
- Глава 6 является, в определенном смысле, продолжением главы 5 применительно к данным, измеренным в порядковых шкалах (или сведенным к таковым различными методами "интервальной" математики);
- Глава 7 объединяет методы статистического анализа "без учителя" и представляет интерес, если исследователь имеет двухмерную таблицу наблюдений, в которой явным образом отсутствует моделируемая величина
Y (т.е. "отклик");
В главе 8 описаны методы анализа "с учителем", когда исследователь располагает некоторой обучающей выборкой – многомерной матрицей варьируемых переменных и сопряженным с нею вектором измерений моделируемой величины Y;
И, наконец, при комплектовании главы 9 мы включили туда методы, которые по своему смыслу довольно мало отличаются от представленных в главе 8, но характеризуются относительной новизной и не слишком долговечной, на наш взгляд, рекламной меткой “ИИ” (искусственный интеллект).
Общее описание и сравнительный обзор всех этих методов выполнен в разделах 4-8 главы 2, где приведена также основная рекомендуемая библиография.
Каждый раздел представляемой части построен по единой стандартной схеме из трех следующих подразделов:
- “
Формулировка задачи”, содержащая общую экологическую и математическую постановку проблемы по принципу описания "мясорубки" (т.е. берем на входе объект “А” и желаем получить на выходе объект “Б”);
- “Математический лист” или краткое описание теоретических идей, используемых при построении статистических моделей и оценки их достоверности (в названии этого подраздела мы отдали должное Э.Т. Гофманну, впервые использовавшему макулатурные листы в "Житейских воззрениях кота Мурра"; читатель, не интересующийся математической "кухней", может их вполне пропустить, иногда, без большого ущерба для понимания существа дела);
- “Результаты расчетов”, содержащие более или менее развернутые примеры использования каждого метода на основе единого тестового массива гидробиологических показателей.
Расчеты, иллюстрирующие изложенные методы, были выполнены на основе одного и того же "сквозного" для всех глав набора исходных измерений: данных гидроэкологического мониторинга донных организмов на 40 малых реках, расположенных в степной и лесостепной зонах Среднего Поволжья (см. карту на рис. 1.8). Подробно структура и информационный состав базы данных описан в разделе 1.6.
Выборка, использовавшаяся при построении статистических моделей, характеризовалась следующими основными параметрами:
- количество водных объектов (малых рек Самарской области) – 34;
- количество станций наблюдений (по выделенным створам рек) –
247;
- количество гидробиологических проб и сопряженных с ними гидрохимических и гидрологических измерений –
571;
- диапазон дат измерений – от 10.07.1985 до 31.07.2000 г.;
- сезонный диапазон дат измерений – с 1 мая по 1 ноября;
- количество видов макрозообентоса –
580;
- количество значений численности и биомассы по видам гидробионтов, полученных в результате обработки всех 571 проб –
5937;
- количество учитываемых качественных и количественных гидрологических показателей –
12;
- количество учитываемых гидрохимических показателей –
18;
- общее количество измерений гидрохимических показателей –
3102.
На рисунках, в таблицах и уравнениях нами использовались следующие условные обозначения для измеренных и рассчитанных показателей применительно к каждой гидробиологической пробе:
S
– число видов макрозообентоса в пробе;
Ni
– численность i-го вида в пробе, экз/м2;
NS – суммарная численность всех видов в пробе;
Bi
– биомасса i-го вида в пробе, мг/м2;
BS – суммарная биомасса всех видов в пробе;
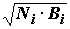
или (Ni×
Bi)0.5 – индекс плотности, рассчитанный для вида в пробе (см. раздел 2.3);
(Ns×
Bs)0.5
– индекс плотности всех видов в пробе;
Н – информационный индекс Шеннона (см. раздел 4.3);
V
– биотический индекс Вудивисса (см. раздел 4.5);
P
– олигохетный индекс Гуднайта-Уитлея-Пареле (см. раздел 4.2);
D
– хирономидный индекс Балушкиной (см. раздел 4.2).
Для формирования обучающей выборки, использованной в главах 8 и 9, по каждому из 571 комплексов измерений нами оценивался класс качества воды по шестибальной шкале в соответствии с ГОСТ 17.1.3.07–82. Эта оценка выполнялась на основе гидрохимического индекса загрязнения воды ИЗВ (см. раздел 3.5), если имелся в наличии необходимый набор из 6 показателей, либо по методике Былинкиной и Драчева (см. раздел 3.6), если имеющихся гидрохимических данных было недостаточно.
При выполнении расчетов мы использовали следующие программные продукты:
- пакет прикладных программ для статистических расчетов
STATISTICA v5.5A, методически наиболее полный на сегодняшний день, но, вследствие "странной стохастичности" видеоинтерфейса, далеко не всегда "дружественный" к пользователю (русскоязычные ссылки в Интернет http://www.statsoft.ru и http://www.exponenta.ru/soft/Statist);
статистическую программу StatGraphics v5.0 для Windows, менее полную, но более гармоничную и "дружественную";
программу статистического анализа на основе нейросетей Statistica Neural Networks v1.0;
превосходную программу статистического анализа Matrix, разработанную А.А. Цыплаковым (Новосибирский госуниверситет) и распространяемую бесплатно на сайте Интернет www.nsu.ru/ef/tsy/ecmr/mtx;
аналитический пакет Deductor, ориентированный на решение задач многомерного анализа и разработанный российской лабораторией BaseGroup Labs, специализирующейся в области искусственного интеллекта (сайт в Интернет http://www.basegroup.ru/labs).
Значительная часть расчетов, реализующих "нестандартные" математические методы и алгоритмы распознавания образов, была выполнена с использованием собственных программных модулей, разработанных авторами и входящих в состав компонентов базы гидробиологических данных по малым рекам Самарской области (СУБД Ac
cess 97, алгоритмический язык Visual Basic for Application).